In today’s post, I will report on some excellent work on MBH98 by Hampus Soderqvist, who discovered an important but previously unknown Mike’s Nature Trick: Mann’s list of proxies for AD1400 and other early steps was partly incorrect (Nature link now dead – but see NOAA or here). Mann’s AD1400 list included four series that were not actually used (two French tree ring series and two Moroccan tree ring series), while it omitted four series that were actually used. This also applied to his AD1450 and AD1500 steps. Mann also used an AD1650 step that was not reported.
Soderqvist’s discovery has an important application.
The famous MBH98 reconstruction was a splice of 11 different stepwise reconstructions with steps ranging from AD1400 to AD1820. The proxy network in the AD1400 step (after principal components) consisted 22 series, increasing to 112 series (after principal components) in the AD1820 step. Mann reported several statistics for the individual steps, but, as discussed over and over, withheld the important verification r2 statistic. By withholding the results of the individual steps, Mann made it impossible for anyone to carry out routine statistical tests on his famous reconstruction.
However, by reverse engineering of the actual content of each network, Soderqvist was also able to calculate each step of the reconstruction – exactly matching each subset in the spliced reconstruction. Soderqvist placed his results online at his github site a couple of days ago and I’ve collated the results and placed them online here as well. Thus, after almost 25 years, the results of the individual MBH98 steps are finally available.
Remarkably, Soderqvist’s discovery of the actual composition of the AD1400 (and other early networks) sheds new light on the controversy about principal components that animated Mann’s earliest realclimate articles – on December 4, 2004 as realclimate was unveiled. Both articles were attacks on us (McIntyre and McKitrick) while our GRL submission was under review and while Mann was seeking to block publication. Soderqvist’s work shows that some of Mann’s most vehement claims were untrue, but, oddly, untrue in a way that was arguably unhelpful to the argument that he was trying to make. It’s quite weird.
Soderqvist is a Swedish engineer, who, as @detgodehab, discovered a remarkable and fatal flaw in the “signal-free” tree ring methodology used in PAGES2K (see X here). Soderqvist had figured this out a couple of years ago. But I was unaware of this until a few days ago when Soderqvist mentioned it in comments on a recent blog article on MBH98 residuals.
The Stepwise Reconstructions
Mann et al (1998) reported that the reconstruction consisted of 11 steps and, in the original SI (current link), reported the number of proxies (some of which were principal component series) for each step – 112 in the AD1820 network and 22 in the AD1400 network. As we later observed, the table of verification statistics did not include Mann’s verification r2 results. Verification r2 is one of the most commonly used statistics and is particularly valuable as a check against overfitting in the calibration period.

Although Mann claimed statistical “skill” for each of the eleven steps, he did not archive results of the 11 individual step reconstructions. In 2003, we sought these results, ultimately filing a formal complaint with Nature. But, to its continuing discredit, Nature supported Mann’s withholding of these results. Despite multiple investigations and litigations, Mann has managed to withhold these results for over 25 years.
Nor did Mann’s original SI list the proxies used in each step. In April 2003, I asked Mann for the location of the FTP site containing the data used in MBH98. Mann replied that he had forgotten the location but his associate Scott Rutherford would respond. Subsequently, Rutherford directed to me to a location on Mann’s FTP site which contained a collation of 112 proxies (datestamped July 2002), of which many were principal component series of various tree ring networks. It’s a long story that I’ve told many times. In the 1400-1449 period of Rutherford’s collation, there were 22 “proxies” including two North American PCs.
In October 2003 (after asking Mann to confirm that the data provided by Rutherford was the data actually used in MBH98), we published our first criticism of MBH98. Mann said that we had used the “wrong” data and should have asked for the right data. Mann also provided David Appell with a link to a previously unreported directory at Mann’s FTP site, most of which was identical to the directories in the Climategate zipfile that Soderqvist subsequently used. This FTP location was dead from at least 2005 on and there is no record of it in the Wayback Machine. (Its robots.txt file appears to have prevented indexing.) At the time, Mann also said that MBH98 had used 159 series, not 112 series. We asked Mann to identify the 159 series. Mann refused. (There was much other controversy).
Ultimately, we filed a Materials Complaint with Nature asking them, inter alia, to (1) require Mann to identify the 159 series actually used in MBH98 and (2) provide the results of the individual steps (described as “experiments” in the SI). Nature, to its shame, refused to require Mann to provide the results of the individual steps (which remain withheld to this day), but did require him to provide a list of the proxies used in each step. In the AD1400 network, it included the four French and Moroccan tree ring series and two North American PCs. This list was published in July 2004 and has been relied on in subsequent replication efforts.
Although Mann refused to provide results of individual steps, the archived reconstruction (link) is a splice of the 11 steps, using the results of the latest step where available. Its values between 1400 and 1449 thus provides a 50-year glimpse of the AD1400 reconstruction. This is a long enough period to test whether any proposed replication is exact. (I recently noticed that the Dirty Laundry data in the Climategate archive provides a second glimpse of values between 1902 and 1980 for the AD1400 and AD1600 networks.)
At different times, McIntyre-McKitrick, Wahl-Ammann and Climate Audit readers Jean S and UC tried to exactly replicate the individual steps in the spliced MBH98 results, but none of us succeeded. When Wahl-Ammann published their code, I was able to reconcile their results to our results to five nines accuracy within a few days of their code release (e.g. link, link). It ought to have been possible to exactly reconcile to MBH98 results, but none of us could do so. The figure below (from May 2005) shows the difference between the Wahl-Ammann version and MBH98 version. At times, the differences are up to 1 sigma. To be clear, the shape of the replication – given MBH data and methods – was close to MBH98 values, but there was no valid reason why it couldn’t be replicated exactly and, given the effort to get to this point, each of us wanted to finish the puzzle.
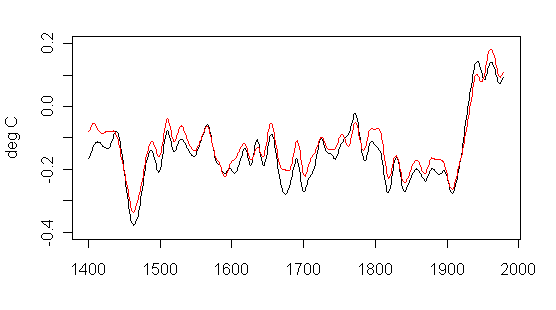
In 2006, Wegman wryly observed that, rather than replicating Mann and disproving us, Wahl and Ammann had reproduced our calculations.

Around 2007, Jean S and UC both tried unsuccessfully to replicate the MBH98 steps. I had posted up scripts in R in 2003 and 2005. UC posted up a clean script in Matlab for MBH replication. Eventually, Jean S speculated that Mann’s list of proxies must be incorrect, but we all eventually gave up.
A few years ago, Soderqvist noticed UC’s script for MBH98 and began reverse engineering experiments in which he augmented the AD1400 network with other candidate proxies available in the Climategate documents (mbh-osborn.zip). This included many series that were not available in the Nature, NOAA or Penn State supplementary information (but, at one time, had been in the now dead UVA archive that had been temporarily available in late 2003 and early 2004, but unavailable in the SI,)
In October 2021, Soderqvist had determined Mann that the AD1400 and AD1450 proxy lists were incorrect and contacted Mann pointing out the errors and required corrections to the SI:
For the AD 1400 and AD 1450 steps, the reconstruction is not a linear combination of the archived proxies. The correct proxy lists can be determined by adding available proxies until the reconstruction is in their linear span. It turns out that PCs 3 to 6 of the NOAMER network have been replaced with proxies that were not used in these time steps. For comparison, the follow-up paper “Long-term variability in the El Niño/Southern Oscillation and associated teleconnections” lists the first six PCs (table 1, entries 89-94).
There is also an undocumented AD 1650 step with its own set of proxies. It is just the AD 1600 set with some additional proxies.
Instead of issuing a Corrigendum or otherwise correcting the SI, Mann and associates buried the information deep in a Penn State archive (see link). The covering text cited Soderqvist, together with Wahl and Ammann, as “two emulations” of the MBH98 reconstruction, ostentatiously failing to mention our original emulation of the MBH98 reconstruction (which exactly reconciled to the later Wahl-Ammann version: see link; link) or emulations by UC or Jean S, on which Soderqvist had relied.
Two more years passed.
Earlier this year, I corresponded with and collaborated with Soderqvist (@detgodehab on Twitter) on his remarkable discovery of a fatal flaw in the popular “signal-free” tree ring methodology used in PAGES2K and now widely popular (see X here).
A few days ago, I posted a thread on MBH98 residuals (link) in which I observed that several datasets connected with notorious Dirty Laundry email contained 1902-1980 excerpts from MBH98 AD1400 and AD1600 steps that had not been previously identified as such. Soderqvist commented on the thread, pointing out (in passing) a quirky Mannian error in calculation of average temperatures that no one had noticed in the previous 25 years.
Impressed once again by his reverse engineering acumen, I posed (or thought that I was posing) the longstanding mystery of reverse engineering the actual list of MBH98 proxies used in the AD1400 step as something that might interest him. I even suggested that the NOAMER PC3 might be involved somehow (on the basis that it was used in the AD1000 step and might have been used in AD1400 step.)

AS it turned out, Soderqvist had not only thought about the problem, but figured it out. And the PC3 was involved.

The information at his github site showed that four series listed in the SI but not actually used were two French tree ring series and two Moroccan tree ring series. They were also listed in the AD1450 and AD1500 networks, but do not appear to have been actually used until the AD1600 network.
A few days ago, Soderqvist archived the results of the individual steps at his github (see link here). I checked his AD1400 results against the 1400-1449 excerpt in the splice version and the 1902-1980 excerpt in the Dirty Laundry data and the match was exact. I’ve additionally collated his results are collected into an xlsx spreadsheet in a second archive here: https://climateaudit.files.wordpress.com/2023/11/recon_mbh-1.xlsx.

So, after all these years, we finally have the values for the individual MBH98 steps that Mann and Nature refused to provide so many years ago.
New Light on An Old Dispute
But there’s another reason why this particular error in listing proxies (claiming use of two North America PCs, rather than the six PCs actually used) intrigued me.
During the original controversy, Mann did not merely list use of two NOAMER PCs in obscure Supplementary Information: he vehemently and repeatedly asserted that he had used two North American PCs in the AD1400 because that was the “correct” number to use under “application of the standard selection rules”. It was a preoccupation at the opening of Realclimate in December 2014, when Mann was attempting block publication of our submission to GRL.
For example, the very first article (scroll through 2004 archives to page 9 link) in the entire Realclimate archive, dated November 22, 2004 – almost three weeks before Realclimate opened to the public on December 10, 2004 – is entitled PCA Details: PCA of the 70 North American ITRDB tree-ring proxy series used by Mann et al (1998). Mann stated that two North American PCs were used in the AD1400 network based on “application of the standard selection rules” applied to short-centered data:

Realclimate opened on December 10, 2004 (link) and, on opening, featured two attacks on us by Mann  (link; link) entitled False Claims by McIntyre and McKitrick regarding the Mann et al (1998) reconstruction and Myth vs Fact Regarding the “Hockey Stick“. Both were dated December 4, 2004. Mann cited our Nature submission as the target of his animus.
(link; link) entitled False Claims by McIntyre and McKitrick regarding the Mann et al (1998) reconstruction and Myth vs Fact Regarding the “Hockey Stick“. Both were dated December 4, 2004. Mann cited our Nature submission as the target of his animus.
In these earliest Realclimate articles, (link; link) Mann vehemently asserted (linking back to the PCA Details article) that they had used two PC series in the MBH98 AD1400 network by application of Preisendorfer’s Rule N to principal components calculated using “MBH98 centering” i.e. Mann’s incorrect short centering:
asserted (linking back to the PCA Details article) that they had used two PC series in the MBH98 AD1400 network by application of Preisendorfer’s Rule N to principal components calculated using “MBH98 centering” i.e. Mann’s incorrect short centering:
The MBH98 reconstruction is indeed almost completely insensitive to whether the centering convention of MBH98 (data centered over 1902-1980 calibration interval) or MM (data centered over the 1400-1971 interval) is used. Claims by MM to the contrary are based on their failure to apply standard ‘selection rules’ used to determine how many Principal Component (PC) series should be retained in the analysis. Application of the standard selection rule (Preisendorfer’s “Rule N’“) used by MBH98, selects 2 PC series using the MBH98 centering convention, but a larger number (5 PC series) using the MM centering convention.
In an early Climate Audit article (link), I tested every MBH98 tree ring and step using Preisendorfer’s Rule N and was unable to replicate the numbers of retained PCs reported in the SI using that rule.
Soderqvist’s discovery that MBH98 used six North American PCs not only refutes Mann’s claim that he used two North American PCs, but refutes his claim that he used Preisendorfer’s Rule N to select two PCs. Soderqvist’s discovery raises a new question: how did Mann decide to retain six North American PCs in the AD1400: it obviously wasn’t Preisendorfer’s Rule N. So what was the procedure? Mann has never revealed it.
Subsequent to the original controversy, I’ve written many Climate Audit posts on properties of principal components calculations, including (some of what I regard as the most interesting) Climate Audit posts on Chaldni patterns arising from principal components applied to spatially autocorrelated tree ring series. The takeaway is that, for a large-scale temperature reconstruction, one should not use any PCs below the PC1. The reason is blindingly obvious once stated: the PC2 and lower PCs contain negative signs for approximately half the locations i.e. they flip the “proxies” upside down. If the tree ring data are indeed temperature “proxies”, they should be used in the correct orientation. Thus, no need for lower order PCs. In many important cases, the PC1 is similar to a simple average of the series. Lower order PCs tend to be contrasts between regional groupings. In the North American network, southeastern US cypress form a grouping that is identifiable in the PC5 (centered) and, needless to say, the stripbark bristlecones form another distinct grouping.
He then observed that, under MM05 (correct) centering, the “hockey stick” pattern appeared in the PC4. For the subsequent inverse regression step of MBH98 methodology, it didn’t matter whether the hockey stick pattern appeared in the PC1; inclusion even as a PC4 was sufficient to impart a hockey stick shape to the resulting reconstruction:
Although not disclosed by MM04, precisely the same ‘hockey stick’ PC pattern appears using their convention, albeit lower down in the eigenvalue spectrum (PC#4) (Figure 1a). If the correct 5 PC indicators are used, rather than incorrectly truncating at 2 PCs (as MM04 have done), a reconstruction similar to MBH98 is obtained
Being a distinct regional pattern does not prove that the pattern is a temperature proxy. “Significance” under Rule N is, according to Preisendorfer himself, merely a “attention getter, a ringing bell… a signal to look deeper, to test further”. See our discussion of Preisendorfer here.
The null hypothesis of a dominant variance selection rule [such as Rule N] says that Z is generated by a random process of some specified form, for example a random process that generates equal eigenvalues of the associated scatter [covariance] matrix S… One may only view the rejection of a null hypothesis as an attention getter, a ringing bell, that says: you may have a non-random process generating your data set Z. The rejection is a signal to look deeper, to test further.
Our response has always been that the relevant question was not whether the hockey stick pattern of the stripbark bristlecones was a distinctive pattern within the North American tree ring network, but whether this pattern was local and specialized, as opposed to an overall property; and, if local to stripbark bristlecones, whether the stripbark bristlecones were magic world thermometers. The 2006 NAS panel recommended that stripbark bristlecones be avoided in temperature reconstructions, but their recommendation was totally ignored. They continued in use in Mann et al 2008, PAGES2K and many other canonical reconstructions, none of which are therefore independent of Mann et al 1998-99.
While most external attention on MBH98 controversy has focussed on principal component issues, when I reviewed the arc of Climate Audit posts in 2007-2008 prior to Climategate, they were much more focused on questions pertaining to properties of the inverse regression step subsequent to the principal components calculation and, in particular, to overfitting issues arising from inverse regression. Our work on these issues got sidetracked by Climategate, but there is a great deal of interesting material that deserves to be followed up on.



















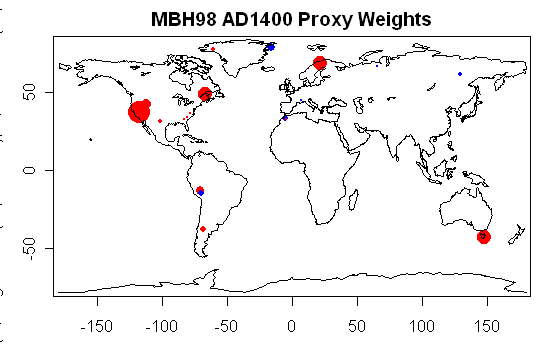







 associated with the notorious “dirty laundry” Climategate email (
associated with the notorious “dirty laundry” Climategate email (



